 sexta-feira, outubro 26, 2018
sexta-feira, outubro 26, 2018

Domingo é eleito o presidente brasileiro
e, no entretanto, as pesquisas têm mostrado uma tendência de queda do candidato Bolsonaro.
Será que essa tendência é verdadeira e coloca em causa a eleição de Bolsonaro ou são apenas oscilações estatísticas sem importância?
Vejamos as 4 últimas pesquisas
| Observado | Corrigido | |||||
| Data | N | Empresa | Bols | Had | Bols | Had |
| 15-Out | 2506 | Ibope | 52 | 37 | 59 | 41 |
| 17-Out | 9137 | Datafolha | 52 | 36 | 59 | 41 |
| 23-Out | 3010 | Ibope | 50 | 37 | 57 | 43 |
| 25-Out | 9137 | Datafolha | 48 | 38 | 56 | 44 |
Tenho que processar estes dados.
Fiz um programinha de bootstrapping e os resultados mostram, a partir das pesquisas, que
1) Há uma tendência muito pequenina de queda de 0,26 pp/dia
-0,26 pp/dia, desv. padrão de 0,1pp => t-stat de -2,64 => estatísticamente significante a 1%.
2) O Bolsonario vai ter, no Domingo, entre 53,4% e 57,7%, com um grau de confiança de 99%.
3) A probabilidade do Bolsonaro perder é inferior 0,01%
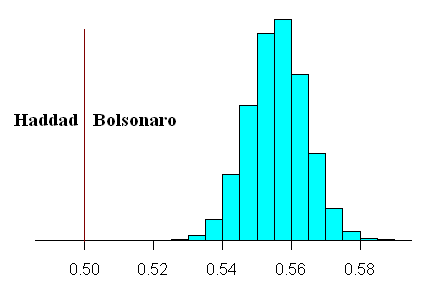
Fig. 1 - Distribuição dos resultados esperados calculados a partir das sondagens
Os resultados (29 de Outubro).
Decorreram as eleições ontem e os resultados forma
Bolsonado = 55,1%
Haddad = 44,9%
Isto compara com o valor mais provável que resulta das pesquisas que era entre 55,0% e 56,0% para Bolsonado (ver, Fig. 1).
Porque não dizer que as notícias que, pegando nas pesquisas, disseram que o Bolsonado poderia perder eram fake news?
#Código que usei no R
A0<- c(rep(0,276),rep(1,1303),rep(2,927))
A1<- c(rep(0,1097),rep(1,4751),rep(2,3289))
A2<- c(rep(0,391),rep(1,1505),rep(2,1114))
A3<- c(rep(0,1279),rep(1,4386),rep(2,3472))
tend<-rep(0,100000)
res<-rep(0,100000)
for (i in 1:100000)
{B0 <- sample(A0,length(A0),rep=TRUE)
B0 <- length(B0[B0==1])/length(B0[B0!=0])
B1 <- sample(A1,length(A1),rep=TRUE)
B1 <- length(B1[B1==1])/length(B1[B1!=0])
B2 <- sample(A2,length(A2),rep=TRUE)
B2 <- length(B2[B2==1])/length(B2[B2!=0])
B3 <- sample(A3,length(A3),rep=TRUE)
B3 <- length(B3[B3==1])/length(B3[B3!=0])
x <- c(0,2,8,10)
y <- c(B0,B1,B2,B3)
d<- data.frame(x,y)
m<- lm(y~x,data=d)
d[5,]<- c(13,0)
tend[i] <-m$coefficients[2]
res[i]<-predict(m,d[5,])
}
mean(res)
hist(res)










1 comentários:
Parabéns Professor. Acertou mesmo na mouche. Um abraço
Enviar um comentário